ZeroMove Technology
ZeroMove hashing algorithm is an innovative novel data distribution technique for distributed systems.
In contrast to the traditional consistent hashing algorithm, which is widely used in distributed data systems and requires
data migration when scaling the system, ZeroMove hashing enables the addition of new clusters
of nodes without moving data between nodes. A cluster is identified using
an encoded unique identifier, while a node is found with a hash function within a cluster.
This approach ensures that data remains in the node where it is hashed, thereby increasing
availability and improving system performance. Furthermore, the ZeroMove hashing technique
can significantly reduce facility and administrative expenses, making it an excellent option
for large-scale distributed systems. Our tests on consistent hashing and ZeroMove
hashing have shown that scaling from one node to six nodes with 480,000 data records took 6100
seconds in a system based on consistent hashing. In contrast, it took only 1.2 seconds for
ZeroMove hashing to achieve similar scaling under the same settings. With consistent hashing,
the time taken and amount of data moved increase proportionally with the amount of data stored in the system.
However, with ZeroMove hashing, these values does not increase in proportion to the amount of
data being stored. This is because ZeroMove hashing only involves the exchange of
small amount of metadata between nodes during scaling processes.
AI Data
Artificial intelligence (AI) systems are trained using large amounts of data to learn and improve their performance.
This is because AI algorithms use statistical techniques to find patterns and make predictions based on the data they
have been trained on. The more diverse and representative the data is, the better the AI will be able
to learn and generalize from that data.
To create accurate and reliable AI models, it is important to ensure that the data used for training is of high
quality, well-structured, and covers a wide range of scenarios and use cases. This allows the AI to learn
from a variety of perspectives and make more accurate predictions or decisions when applied to new data.
Therefore, having lots of good data is essential for developing robust and accurate AI models that can be applied
in a variety of contexts and provide value to businesses and individuals alike. Good data comes from a well-managed
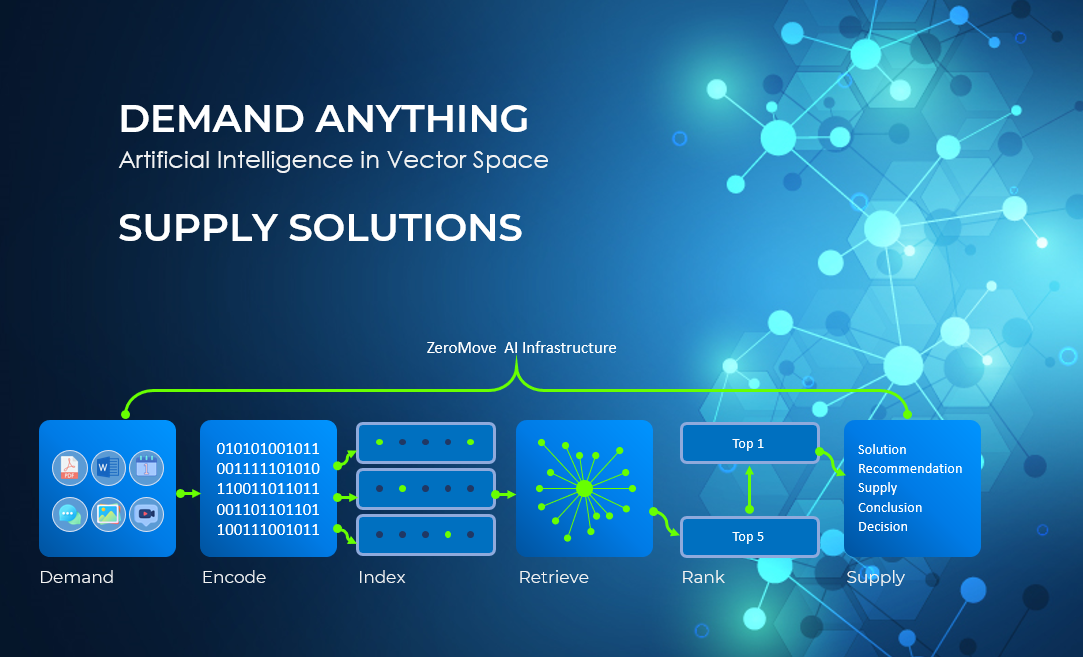
database where knowledge and facts are maintained and fed to the AI systems to reach another level of intelligence.
The vector database in JaguarDB can store and index the embeddings of image and text data for fast search in a multi-node
distributed architecture which can be easily scaled out horizonally more than a million time faster than any other
distributed databases. The distributed storage technology also makes storing large volumes of raw data like videos, images
easier than ever.
|
